随着信息化建设的不断发展,如何有效利用公交企业在运营过程中产生的大量数据信息,进而为公交企业提供决策服务,其中数据仓库技术作为一种管理技术,能够实现数据分析,并起到决策支持作用,进一步推进公交信息化管理水平。
1、数据仓库
数据仓库(Data Warehouse)是一个面向主题的(Subject Oriented)、集成的(Integrate)、相对稳定的(Non-Volatile)、反映历史变化(Time Variant)的数据集合,用于支持管理决策。主要用于数据挖掘和数据分析,辅助领导做决策。数据仓库具有面向主题、集成、随时间变化和数据不可更新等特点。
数据仓库架构分为数据采集层、数据仓库层和数据应用层。采集层主要包括日志、数据库数据、文档数据等需要处理的数据;仓库层是对源数据进行处理后的数据,并通过一系列算法技术进行数据模型的建立,以便满足用户分析需求;应用层数据是完全为了满足具体的分析需求而构建的数据,包括报表查询分析,数据挖掘及可视化分析等。数据仓库架构图如下所示:
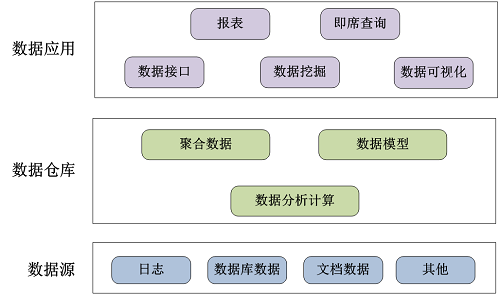
2、数据仓库的关键技术
数据仓库技术是为了有效的把操作型数据集成到统一的环境中以提供决策型数据访问的各种技术和模块的总称。所做的一切都是为了更快更方便查询所需要的信息,提供决策支持。
(1)并行处理技术
并行处理技术是计算机系统同时执行两个或更多个处理的一种计算方法,并行处理技术主要分为共享存储系统、分布式系统和基于GPU的并行处理。面对信息时代所产生的海量数据,利用并行处理技术可以现实数据的率管理,能够节省大型和复杂问题的解决时间。
(2)数据分析技术
数据分析技术是针对大数据运行需要巨大的计算和存储资源的解决方案,采用Hadoop、Spark、云存储、云计算等分布式处理方式实时分析海量的定位数据,同时采用MapReduce模型技术用于大规模数据集的并行运算,实现智能化、率的计算和分析。Hadoop是一个分布式计算平台,可以在Hadoop上开发和运行处理海量数据的应用程序,Hadoop生态系统主要由HDFS、MapReduce、Hbase、Zookeeper、Oozie、Pig、Hive等核心组件构成,高可靠、高扩展、高有效、高容错等特性使Hadoop成为的大数据分析系统。Spark提供强大的内存计算引擎,几乎涵盖了所有典型的大数据计算模式,包括迭代计算、批处理计算、内存计算、流式计算(Spark Streaming)、数据查询分析计算(Shark)以及图计算(GraphX)。Spark支持分布式数据集上的迭代式任务,可以在Hadoop文件系统上与Hadoop一起运行。
(3)数据挖掘技术
数据挖掘(Data Mining,DM)技术是从大量的、不完全的、有噪声的、模糊的、随机的实际应用数据中,提取隐含在其中的、人们事先不知道的、但又是潜在有用的信息和知识的过程。数据挖掘是一种决策支持过程,它主要基于人工智能、模式识别、数据库、可视化技术等,高度自动化地分析企业的数据,做出归纳性的推理,从中挖掘出潜在的模式,帮助管理者做出正确的决策。
3、数据仓库技术的应用
(1)数据化精准运营
通过数据仓库技术实现精准化运营管理,对海量上传到服务器的实时定位信息进行数据化管理,及时获取车辆位置、车速等车辆运营数据,便于完善行车作业计划,合理调度车辆,精准制定班次,实时优化公交线网,进一步满足乘客出行需求。
同时通过对大数据检测分析实现车辆防疫,实现乘客信息追溯,完善车辆防疫流程。实现定制公交精准化、个性化服务,满足乘客多元化出行需求。实现车辆精准发现,线路调度应急管理,确保车辆行车安全,提升运营管理水平。

(2)数据分析挖掘
数据分析挖掘是为了完善调度系统,公交调度数据挖掘的对象是智能调度系统数据库,根据营运调度的实时上传数据,进行数据分析挖掘。
对搜集的原始信息进行分析整理,对海量的数据信息进行清算过滤,将无效数据、错误数据、重复数据等进行详细分类整理。同时进行营运调度问题与偏差分析,调度人员根据不同的问题采取相应的调度措施,便于及时调整车辆调度。确保发车间隔、发车时间、发车次序等正常化。数据分析构建挖掘模型为了发挥数据信息的应用价值,将数据信息进行多样式多方位分析,确保正常营运的同时准确预测未来一定时间内各项营运指标。进而能够根据智能调度系统进行优化调度,推动智慧公交的进一步发展。
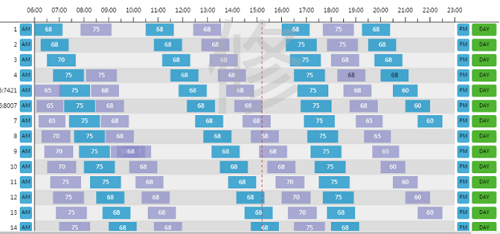
(3)车辆发车间隔、到站时间分析
通过数据仓库技术实现车辆发车间隔、车辆到站时间的分析,对实时上传的线路、到离站、时间、车速等原始定位数据进行筛选计算,利用聚类分析等算法确定车辆有效运行时间范围,实现车辆到站时间的推算和分析。
同时运用遗传算法对车辆发车间隔实现优化计算,建立目标函数对模型进行设计,包括公交运营、服务等,通过二进制编码形式进行初始化,然后计算适度值并选择新的临界种群,根据交叉、变异对其进行适度值计算,根据适度值筛选出结果,便于提高车辆利用率,降低运营成本,减少乘客候车时间。
4、结语
济南公交充分运用数据仓库技术实现公交信息化管理,对运营数据分析挖掘,实现数据化运营和精准运营,为济南公交营运调度及乘客服务提供有力支撑。
文章源自:济南市城市交通研究中心
声明:本网站发布内容和图片的目的在于传播更多信息,归原作者所有,不为商业用途,如有侵权敬请作者与我们联系删除。
上一条 : 部分城市老年人公交补贴政策介绍

